42Maru
~
I worked on several NLP tasks as a Machine Learning Engineer in 42Maru, with a special focus on text summarization.
Company
42Maru is a Korean start-up, based in Seoul. They run QA (Question Answering) solutions based on deep-learning.
Projects
NLP Research
When I joined the company, my first tasks were focused on research for several NLP tasks :
- English paraphrasing : I learned and worked with
Keras, and implemented a Pervasive Attention neural network. - Document Similarity : I started to work on this project right after BERT came out, so I extensively studied the architecture.
I used BERT as service, and implemented a Siamese network on top of it, usingKeras. This architecture lead to great results on the SICK and STS-B datasets. - Machine Reading Comprehension : After trying to improve the score of the previous model (using
Tensorflow) of the company, we implemented 2 API (English + Korean) to make these MRC models available through a website (usingFlask) :
- Question Generation : In order to improve the MRC model through data augmentation, a coworker and I implemented a basic attentional encoder-decoder architecture (in
Pytorch) for question generation.
We then improved the performance by usingBERTas encoder (andLSTMas decoder) and achieved SOTA onSQuADdataset for QG :
| Previous SOTA | Our Model | |
|---|---|---|
| BLEU 1 | 45.07 | 49.85 |
| BLEU 2 | 29.58 | 36.79 |
| BLEU 3 | 21.60 | 29.36 |
| BLEU 4 | 16.38 | 23.98 |
Text Summarization
Text Summarization was my main task while working at 42Maru.
I developed several models beating the SOTA in English text summarization, and built a production-ready, controlable demonstration.
After learning the basics of text summarization, I used Presumm as a starting point (because it was the current SOTA), and integrated XLNet, a newer model. I could improve the current SOTA on CNN/DM dataset in both Extractive and Abstractive summarization :
Extractive summarization :
| PreSumm (Previous SOTA) | Ours | |
|---|---|---|
| ROUGE 1 | 43.23 | 43.73 |
| ROUGE 2 | 20.24 | 20.50 |
| ROUGE L | 39.63 | 40.08 |
Abstractive Summarization :
| PreSumm (Previous SOTA) | Ours | |
|---|---|---|
| ROUGE 1 | 42.13 | 42.60 |
| ROUGE 2 | 19.60 | 20.16 |
| ROUGE L | 39.18 | 39.67 |
In addition to better scores, my contributions allowed to generate summary from documents of any length, while the original PreSumm code has a limitation on the input document’s length.
Later, new models (BART, PEGASUS, etc…) were released, beating the SOTA by a large margin. I studied these models and their framework (transformers, fairseq).
I could improve BART model by adding a mecanism allowing us to control the abstractiveness of the generated summaries, without even re-training the model ! This mecanism also gave better results :
| BART (Previous SOTA) | Ours | |
|---|---|---|
| ROUGE 1 | 44.16 | 44.86 |
| ROUGE 2 | 21.28 | 21.60 |
| ROUGE L | 40.90 | 41.77 |
But BART is a big model, and the GPU available at the company weren’t big enough for training.
So I used free TPU trial from Google to train BART. In order to do this, I had to port the transformers implementation of BART (written in Pytorch) to Tensorflow 2.
With my implementation I could train BART for both Extractive and Abstractive summarization (multi-task learning), achieving even better scores on Abstractive summarization :
| BART (Previous SOTA) | Ours | |
|---|---|---|
| ROUGE 1 | 44.16 | 45.20 |
| ROUGE 2 | 21.28 | 21.69 |
| ROUGE L | 40.90 | 42.14 |
On Extractive summarization the model have similar performance with the SOTA, but with a much faster inference time (800ms vs 50ms) :
| MatchSum (Previous SOTA) | Ours | |
|---|---|---|
| ROUGE 1 | 43.93 | 43.73 |
| ROUGE 2 | 20.79 | 20.87 |
| ROUGE L | 39.97 | 40.03 |
Having a single model for both tasks allow a much smaller memory footprint for deploying models in production.
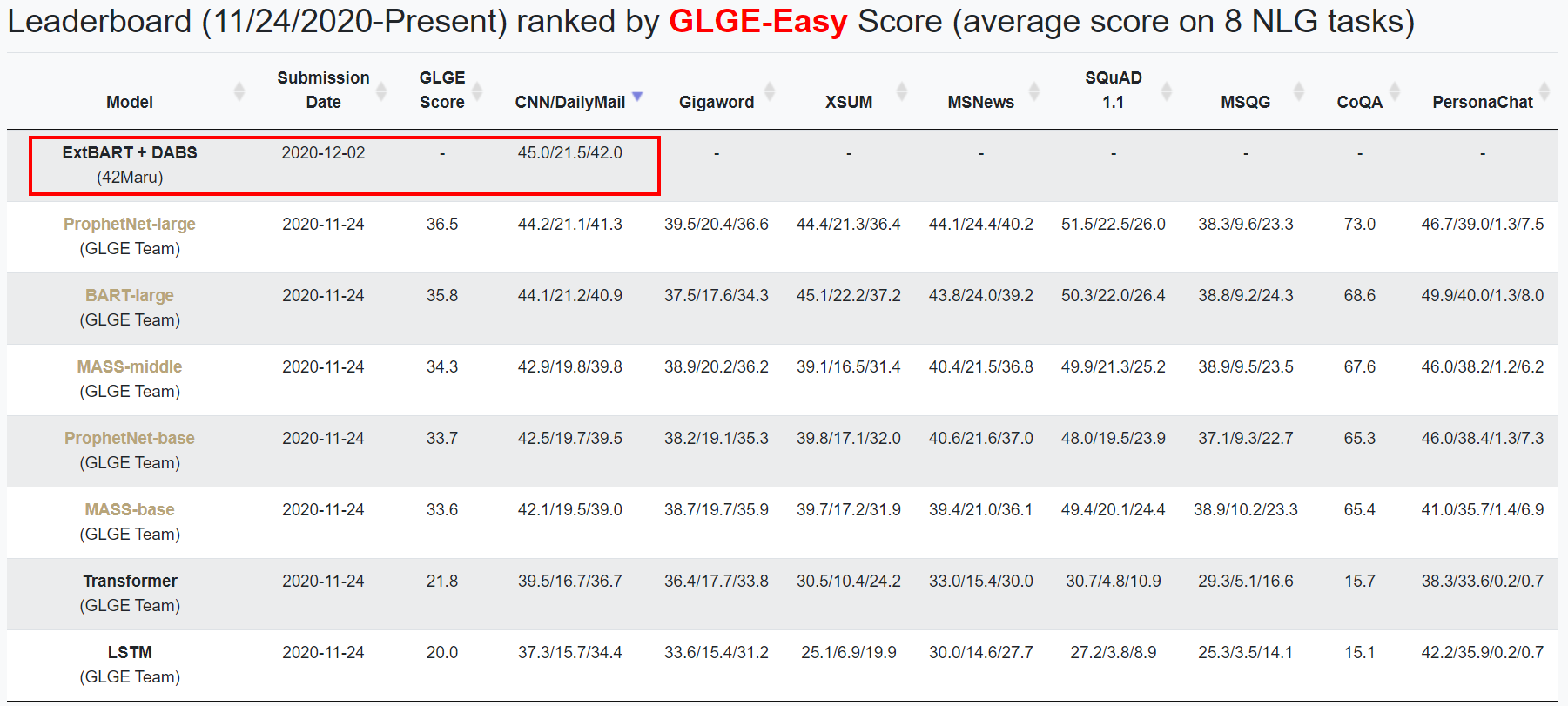
My model officially achieve SOTA on the GLGE benchmark from Microsoft (on CNN/DM dataset) :
PyTorch serving framework
I created a framework used to easily deploy any Pytorch models to production.
Initially only used for the Text Summarization project, more and more people within the company started to use it, and is now used across several projects where we need scalability.
I learned a lot about parallel processing, pipelining, and used libraries such as FastAPI, ZeroMQ, Pydantic, msgpack.
The project is heavily documented and unit-tested, as well as benchmarked.
Intelligent PDF parser
Extracting structured data from unstructured format such as PDF is not a trivial task. Because several projects relies on PDF files in 42Maru, I was assigned the task of developing a project-independent library that can be used to extract actual document contents from PDF files.
While the task seems not too difficult at first, it is actually challenging because every project have different type of PDF format, with their own particularities. A few challenges I faced :
- Ordered title detection
- Headers / Footers detection
- Text order (some files have 2 columns, some don’t)
- etc…
I had to integrate machine learning into the library (altered version of K nearest neighbors) in order to overcome these challenges.
Others
During my professional life in 42Maru, I also had various smaller tasks, from which I learned a lot :
- Setup GPU servers.
- Setup a secure, private PyPi index for the company.
- Find and remove a virus from our server, and add security after resetting the server.
What I learned
Being the first foreigner of the company is tough ! But at the same time, integration was super easy, because I was surrounded by amazing people who made plenty of efforts toward me.
I learned so much from the great people of this company. They have great technical knowledge in their field, and they truly inspired me.
I undoubtedly enjoyed working here, and can’t imagine a better job right after graduation. Every single project that I worked on taught me a lot, and I loved working on every single one of these projects.